介绍Solr的功能以及搭建步骤,主要包括管理核心(core)、索引数据、中文分词、按权重搜索、高亮搜索内容等功能
Solr是Apache公司的一个基于Lucene框架的开源全文搜索服务器
Solr如其在官网宣传的,有如下特性
- 先进的全文搜索能力:支持使用短语、通配符、集合、聚合等进行搜索
- 为高通量网络环境优化过
- 标准的开放接口:使用xml、json、http进行搜索和配置
- 有功能全面的网页管理界面:使用自带的管理网页可以实现Solr支持的大部分功能:监控、配置、搜索
- 易监控:使用JMX发布标准化的运行数据,自带slf4j日志,直接可在网页中查看
- 可伸缩高可用:基于apache zookeeper ,易于服务器复制、分发、负载均衡
- 易修改:每个核心(core)只需要修改两个配置文件就能作绝大部分功能的配置
- 近实时索引
- 易使用插件进行拓展:分词器、查询处理器都可以用自己的jar包定制
- 富文本索引:支持对pdf、word等富文本进行索引
Solr官方文档
Solr官方的quickstart文档http://lucene.apache.org/solr/quickstart.html ,直接搭建一个2个服务器2个shard组成的搜索服务器,帮助对solr的数据索引、搜索、分布式结构有所了解。缺点时文档使用的很多命令只在linux下生效,可以结合下文的使用流程使用windows下能用的命令
Solr官方文档 https://cwiki.apache.org/confluence/display/solr/About+This+Guide 这是在线版的官方文档,有所有功能的介绍,但是举例和异常处理方式不大详细,没有对中文的特殊处理。网络上介绍solr的博客类文档恰好能补充,但因为solr版本繁杂,需要对照官方文档阅读。
Solr初步使用流程
下文介绍一个solr安装使用的例子,目标是对一批简历数据进行搜索。
例中软件环境
| 软件名称 | 软件版本 |
|---|---|
| 操作系统 | Windows10 |
| JAVA版本 | Java8 |
| Solr版本 | Solr6.6.0 |
| 中文分词器 | IK |
使用流程
1.下载安装Java
目前版本的solr最低需要Java8,下载并安装。
2.下载Solr并解压
官方下载页 http://lucene.apache.org/solr/mirrors-solr-latest-redir.html 下载后是个压缩包,解压后就算安装完成了
3.运行solr服务器
通过bin目录下的solr文件启动solr服务器,例如:1
bin\solr start -p 8983
其中-p 8983是指定端口的参数,如果不指定默认开启的端口也是8983.
4.创建核心(core)
核心(core)是solr的一种概念,同一个core中使用同一份字段类型定义、同样的查询配置。搜索时也是需要指定某一个core进行查询的。
使用指令:1
bin\solr create -c corename1
创建一个叫corename1的core。
或者,在http://localhost:8983/solr/#/ 的管理网页上的coreadmin菜单中也可以创建一个core
5.根据目标数据配置schema
#Schema的意义
搜索服务器建立数据索引的过程其实是按照固定格式导入数据,如何定义导入数据的格式就是由schema决定的了。schema定义了一些字段类型(field type)和字段(field),如果把要导入的数据类比为java中的对象,字段类型(field type)和字段(field)就类似于java中的变量类型和变量。在创建一个core之后,会自动在对应的core目录下的conf文件夹生成一个 managed-schema文件,这是由solr实时修改的schema配置文件,原则上不能直接修改。需要配置可以在网页端的schema页面进行修改。
#Schema.xml文件关系
如果要批量修改schema的字段配置,可以直接编辑文件schema.xml。在config目录下和schema配置相关的有这么三个文件: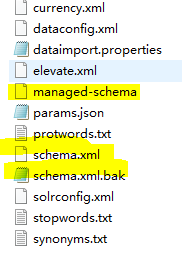
一般技术博客会提到的文件是schema.xml,但是在6.6.0版本中schema.xml文件是不存在的,需要用户自己创建。他们之间的关系如下;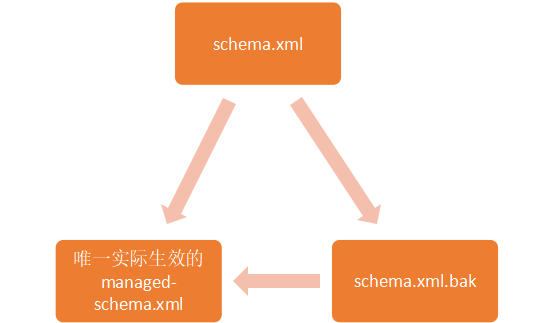
由关系图可见,要编辑schema文件,需要先删除managed-schema.xml和schema.xml.bak文件,自定义schema.xml,如果服务器重启后正确生成了managed-schema.xml和schema.xml.bak那说明配置成功,否则需要查看报错日志,修改schema.xml中的错误。
在初次配置之后想要修改配置文件,那就只需要修改schema.xml.bak再删除managed-schema.xml重启就行了。
Schema.xml文件内容格式
Schema中主要内容是field和field type的定义。自动生成的managed-schema中有不少通用的field和field type定义,要自定义时可以仿照。
field定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<field name="school" type="text_ik" default="" indexed="true" stored="true"/>
```
这个例子里是五个常用的field属性
| |
| :-------- | --------:
| name | 字段名,和要导入数据的字段名要一一对应
| type | 字段类型,要等于某个fieldtype
| default | 默认值
| indexed | 是否被索引,只有被索引的字段才能用于搜索
| stored | 是否被保存,只有被保存的字段才能被搜索后获取
更多属性见https://cwiki.apache.org/confluence/display/solr/Defining+Fields
field type定义:
正如java中的类型一样,text、long……等常用类型已经在自动生成的配置中有了,对中文搜索来说,最重要的需要新定义的field type应该是中文文本类型了。定义前需要选定中文分词器,我试过两种smartcn和ik分词。
smartcn是solr下载后自带的,在solr-6.6.0\contrib\analysis-extras\lucene-libs\ lucene-analyzers-smartcn-6.6.0.jar。但是smartcn是纯粹的计算分词,没有使用分词表进行拓展。拷贝jar包到solr-6.6.0\server\solr-webapp\webapp\WEB-INF\lib下(solr-6.6.0\server\solr-webapp\下的目录结构类似于j2ee网站的结构),并在schema.xml中如此配置:
``` javascript
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
Ik分词版本较多,而且github上的版本已经很旧了,但是它支持使用分词表帮助分词。
依然是把jar包放到solr-6.6.0\server\solr-webapp\webapp\WEB-INF\lib下,把剩下的一个xml和两个dc文件放到solr-6.6.0\server\solr-webapp\webapp\WEB-INF\classes下,然后在schema.xml中加入如下内容1
2
3
4
5
6
7
8
9<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt"/>
</analyzer>
</fieldType>
fieldtype定义好中文类型后,在field中指定对应的类型,之后的索引和搜索对于中文处理就变得简单了。
6 .建立索引/导入数据
Solr支持的导入数据来源有数据库\xml\json\富文本。
导入xml\json\富文本
可以使用网页、命令行方式、api方式导入数据,目前看来在win10中网页导入文本文件有bug,就先介绍命令行方式这种最快的方式。
导入文件要使用post工具,官方文档的指令在windows下不能使用,在命令行中输入类似指令:1
java -Dc=[corename] -Dauto=yes -Ddata=files -Drecursive=yes -jar example/exampledocs/post.jar G:\abc\*.json
需要填写的两个参数:dc是目标core的名字;最后用空格隔开的是目标文件,支持直接使用文件名和通配符,上面的例子指导入abc目录下所有.json文件。
如果导入的是富文本文件,富文本的内容不会像解析json一样按字段存储,而是存储为文件信息和内容两部分。
导入数据库表
涉及到solr唯二配置文件中的solrconfig.xml,在solrconfig.xml中额外指定dataconfig.xml,用于设置数据库连接参数、查询语句、数据库字段与solr field的对应关系1
2
3
4
5<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">conf/dataconfig.xml</str>
</lst>
</requestHandler>
以搜索简历为例,dataconfig.xml:中这样设置:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<!-- The first element is the dataSource, in this case an HSQLDB database.
The path to the JDBC driver and the JDBC URL and login credentials are all specified here.
Other permissible attributes include whether or not to autocommit to Solr, the batchsize
used in the JDBC connection, a 'readOnly' flag.
The password attribute is optional if there is no password set for the DB.
-->
<dataSource driver="oracle.jdbc.driver.OracleDriver" url="jdbc:oracle:thin:@172.29.88.178:1521:DBTEST" user="resumetest" password="resumetest"/>
<!--
Alternately the password can be encrypted as follows. This is the value obtained as a result of the command
openssl enc -aes-128-cbc -a -salt -in pwd.txt
password="U2FsdGVkX18QMjY0yfCqlfBMvAB4d3XkwY96L7gfO2o="
WHen the password is encrypted, you must provide an extra attribute
encryptKeyFile="/location/of/encryptionkey"
This file should a text file with a single line containing the encrypt/decrypt password
-->
<!-- A 'document' element follows, containing multiple 'entity' elements.
Note that 'entity' elements can be nested, and this allows the entity
relationships in the sample database to be mirrored here, so that we can
generate a denormalized Solr record which may include multiple features
for one item, for instance -->
<document>
<!-- The possible attributes for the entity element are described below.
Entity elements may contain one or more 'field' elements, which map
the data source field names to Solr fields, and optionally specify
per-field transformations -->
<!-- this entity is the 'root' entity. -->
<entity name="resume" query="select * from RESUME"
deltaQuery="select id from item where LAST_UPDATE_DATE > '${dataimporter.last_index_time}'" pk="id" transformer="ClobTransformer">
<field column="RESUME_ID" name="id" />
<field column="TAG_ID" name="tagID" />
<field column="STAGE_ID" name="stageId" />
<field column="DEPT_ID" name="deptId" />
<field column="FLAG" name="flag" />
<field column="RESUME_NUMBER" name="resumeNumber" />
<field column="NAME" name="name" />
<field column="SEX" name="sex" />
<field column="POSITION" name="position" />
<field column="POSITION_DETAIL" name="positionDetail" />
<field column="EDUCATION" name="education" />
<field column="SCHOOL" name="school" />
<field column="PHONE" name="phone" />
<field column="EMAIL" name="email" />
<field column="ADDRESS" name="address" />
<field column="BIRTHDAY" name="birthday" />
<field column="HEIGHT" name="height" />
<field column="WEIGHT" name="weight" />
<field column="GRADUATION_DATE" name="graduationDate" />
<field column="HEALTH_CONDITION" name="healthCondition" />
<field column="MARITAL_STATUS" name="maritalStatus" />
<field column="REGISTERED_PLACE_BEFORE" name="registeredPlaceBefore" />
<field column="IDENTITY_CARD_NUMBER" name="identityCardNumber" />
<field column="OVERSEAS_EXPERIENCE" name="overseasExperience" />
<field column="POLITICAL_STATUS" name="politicalStatus" />
<field column="CITY" name="city" />
<field column="EMERGENCY_PHONE" name="emergencyPhone" />
<field column="NATIONALITY" name="nationality" />
<field column="NATIVE_PLACE" name="nativePlace" />
<field column="SELF_EVALUATION_TITLE" name="selfEvaluationTitle" />
<field column="SELF_EVALUATION_CONTENT" name="selfEvalutionContent" clob="true"/>
<field column="SCHOLARSHIP_LEVEL" name="scholarshipLevel" />
<field column="STUDENT_LEADER" name="studentLeader" />
<field column="SCHOOL_ACTIVITY" name="schoolActivity" />
<field column="AWARD" name="award" />
<field column="CERTIFICATE" name="certificate" />
<field column="ENGLISH_LEVEL" name="englishLevel" />
<field column="ENGLISH_SCORE" name="englishScore" />
<field column="ENGLISH_CERTIFICATE1" name="englishCertificate1" />
<field column="ENGLISH_CERTIFICATE2" name="englishCertificate2" />
<field column="LANGUAGE" name="language" />
<field column="COMPUTER_SKILL" name="computerSkill" />
<field column="INTEREST" name="interest" />
<field column="EXPECTED_JOB" name="expectedJob" />
<field column="EXPECTED_CITY" name="expectedCity" />
<field column="EXPECTED_SALARY" name="expectedSalary" />
<field column="CREATED_BY" name="createdBy" />
<field column="CREATION_DATE" name="CreationDate" />
<field column="LAST_UPDATED_BY" name="lastUpdateBy" />
<field column="LAST_UPDATE_DATE" name="lastUpdateDate" />
<field column="VERSION" name="version" />
<field column="MAJOR" name="major" />
<field column="BK_MAJOR" name="bkMajor" />
<field column="TAG_NOTE" name="tagNote" />
<field column="CHECK_IN_FLAG" name="checkinFlag" />
<field column="FROZEN_FLAG" name="frozenFlag" />
</entity>
</document>
</dataConfig>
配置完毕后,使用网页操作导入数据
7.进行标准查询
导入数据后,在solr的网页中就可以进行查询了,可配置参数如下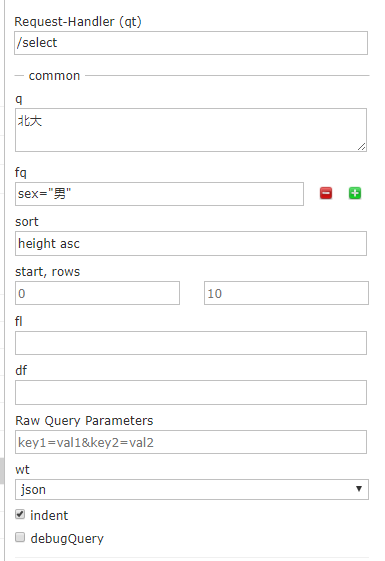
我填写的这些参数的含义:
| |
| :——– | ——–:
| q| 搜索内容
| fq| 对结果进行过滤,对某些字段的严格限制,类似于sql语句中的where field=value
| sort | 排序字段,使用字段+空格+asc/desc表示排序方式
| start rows| 两个分页字段
| fl| 类似于sql的投影,限制返回的字段
| df | 限制被查询的字段
| wt | 结果返回的格式
| indent true or false |控制结果是否缩进
| debug| 返回结果中显示哪些debug信息,query/timing/results/all(true)备选
更多参数见https://cwiki.apache.org/confluence/display/solr/Common+Query+Parameters#CommonQueryParameters-ThesortParameter
8搜索结果的初步优化——edismax搜索和编辑分词表、停用词表
搜索简历的过程中,遇到下面几种情况:
| | |
| :——– | ——–| ——–:
| 搜索“南大”、“北大”,首先出来的是“东南大学”“东北大学”| solr认为文字的完全匹配有最高优先级,就算设置了同义词,搜索“南大”,东南大学和南京大学的比重也是等同的| 对于明显有特指的大学简称,设置单向同义词。在同义词表solr-6.6.0\server\solr\resume5\conf下,新增 北大 => 北京大学 的配置,对于其它常用大学简称,都设置双向同义词 西南财经大学,西南财大,西财,SWUFE
|某些大学缩写不被识别,搜索“南农”,会返回对“南”的搜索和“农”的搜索|正常语境中“X大”“上X”类的词语确实不该独立成词,但是在简历这种情况下需要这些词语成立| 对大学同义词表中的所有简称词,添加到拓展词典\solr-6.6.0\server\solr-webapp\webapp\WEB-INF\classes\mydict.dic中
| 搜索姓名“X波”,结果中地址、专业、简介的“电磁波”干扰了我的目标| 所有字段权值一样,姓名被分词后再各字段里都会出现|使用dismax/edismax搜索方式,给搜索的字段加上权重,给姓名和学校赋予最高权值。因为solr默认的算法设置中,对于“地址”这个20-30字的字段最容易返回,因此适当降低了搜索时对于“地址”的权重
edismax的参数如下: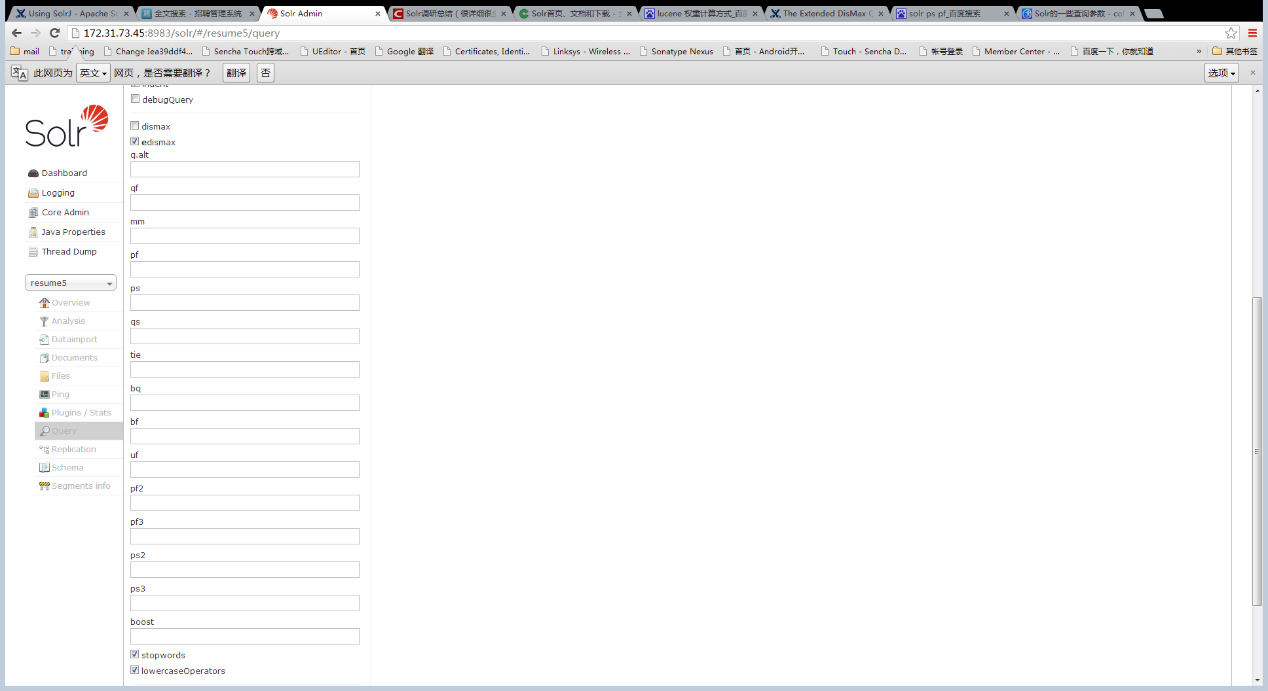
常用参数设置:
| |
| :——– | ——–:
| q.alt| 当标准查询参数q不存在时生效的参数
| qf| 查询权重,格式字段名^权重 字段名^权重,默认权重为1。没有列出的字段不会被查询
| mm|结果返回数量,可以是数字和百分数的组合 3 代表只留3个;75%表示只留搜索结果的前75%;3<75%表示最少保留max[3,75%]个结果;-号代表要去除的结果数量,如-3代表只去除3个结果
| pf| 排序权重,参数格式和qf完全一样,但是它不会把不符合的结果去除掉,只影响排序。
edismax搜索还可以使用bf参数做自定义权值,参考https://cwiki.apache.org/confluence/display/solr/The+DisMax+Query+Parser ,如果数据里有重要的数字、频率如点击率、发布日期……可以考虑用bf写一个简单的自定义权值。因为简历主要是文本,手写文档关系的算法比较复杂,我选择就使用qf,依赖于lucene的文档关系算法。
9.使用java借助solr搜索
solr的外部调用方式很多,直接使用js写post请求访问solr服务器、对java\ruby\python都有调用API。Java的api比起直接用js,优点是不用自己拼查询url。对于maven项目,只需要添加1
2
3
4
5<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>6.6.0</version>
</dependency>
就足够调用solrj了,但是要下载的文件比较多,更新maven慢。Java代码中关键的代码不多,像下面的代码就已经能发起一次标准查询了。1
2
3
4
5
6
7
8
9SolrClient solr = new HttpSolrClient.Builder(solrUrl).build();
SolrQuery query = new SolrQuery();
query.setQuery(searchParams.getQueryString());
query.set("start", start);
query.set("rows", limit);
query.set("wt", "json");
QueryResponse rsp = solr.query(query);
SolrDocumentList docs = rsp.getResults();
Solr的高亮只需要一个hl参数,但是高亮哪些字段受到qf字段(dismax查询的权重字段)、hl.fl字段的影响。在没有设置qf时,hl.fl代表哪些字段会高亮,有qf时以qf为准。1
2
3
4
5
6
7
8
9query.setHighlight(true);
query.set("defType", "dismax");
query.set("hl.fl","*");
query.set("hl.usePhraseHighlighter",true);
query.set("hl.highlightMultiTerm",true);
query.set("hl.simple.pre","<span class=\"highlight\">");
query.set("hl.simple.post","</span>");
query.set("qf","school^90 name^90 address^0.05 resumeNumber^1 position^90 education^1 major^5 telephone^1 mail^1");
返回的高亮部分内容是作为一个独立的结构返回的,和我们在baidu、google搜索引擎里看到的结果不大一样。需要在获取后做一个处理:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36hlDocs.setNumFound(docs.getNumFound());
Map<String,Map<String,List<String>>> tempMap = rsp.getHighlighting();
for(int i=0;i<docs.size();i++) {
SolrDocument doc = docs.get(i);
if (null!=tempMap.get(doc.getFieldValue("id")).get("name")) {
doc.setField("name", tempMap.get(doc.getFieldValue("id")).get("name"));
}
if(null!=tempMap.get(doc.getFieldValue("id")).get("school")) {
doc.setField("school", tempMap.get(doc.getFieldValue("id")).get("school"));
}
if(null!=tempMap.get(doc.getFieldValue("id")).get("address")) {
doc.setField("address", tempMap.get(doc.getFieldValue("id")).get("address"));
}
if(null!=tempMap.get(doc.getFieldValue("id")).get("resumeNumber")) {
doc.setField("resumeNumber", tempMap.get(doc.getFieldValue("id")).get("resumeNumber"));
}
if(null!=tempMap.get(doc.getFieldValue("id")).get("position")) {
doc.setField("position", tempMap.get(doc.getFieldValue("id")).get("position"));
}
if(null!=tempMap.get(doc.getFieldValue("id")).get("education")) {
doc.setField("education", tempMap.get(doc.getFieldValue("id")).get("education"));
}
if(null!=tempMap.get(doc.getFieldValue("id")).get("major")) {
doc.setField("major", tempMap.get(doc.getFieldValue("id")).get("major"));
}
if(null!=tempMap.get(doc.getFieldValue("id")).get("telephone")) {
doc.setField("telephone", tempMap.get(doc.getFieldValue("id")).get("telephone"));
}
if(null!=tempMap.get(doc.getFieldValue("id")).get("mail")) {
doc.setField("mail", tempMap.get(doc.getFieldValue("id")).get("mail"));
}
hlDocs.add(doc);
}
return hlDocs;
到这一步已经能做出一个较为完整的搜索简历的服务了。但是字段的权值、中文分词得不断根据实际数据变化和用户反馈改进才行,下面是一些能提高solr搜索结果满意度的方法。
Solr功能拓展
1.聚类搜索
很多网站提供的分类别搜索,在solr里配置facet相关参数就可以做到。
facet常用参数如下:
facet.field代表要分类的字段,如果要分类多个字段,需要再设置一个facet字段。返回结果会在通常的查询结果后缀一个分类查询结果,如下图:
facet分类还支持根据时间分类、根据数字区间分类、分类过滤,详细内容见https://cwiki.apache.org/confluence/display/solr/Faceting#Faceting-Thefacet.fieldParameter
2.拼音搜索
增加拼音搜索的功能只要有能识别拼音的分词器就行了,找到拼音分词的jar包放到
WEB-INF/lib目录下,配合smartcn分词包或ik分词包使用。然后依然是在schema.xml中定义新的fieldtype1
2
3
4
5
6
7
8
9
10
11
12
13
14<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="6" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="6" maxGram="20" />
</analyzer>
</fieldType>
3.相似数据推荐
类似于大多数网站的相似产品推荐,solr也提供了这种功能——morelikethis。通过制定搜索结果和某个字段,solr查找出在该字段上与当前搜索结果类似的结果。如果字段配置了termVectors=”true”,那么推荐会更加准确。下面这个搜索代表搜索resumeid为58901简历的类似简历,以专业为主要关联字段。1
select? resumeId=58901&mlt=true&mlt.fl=major&mlt.mindf=1&mlt.mintf=1&wt=json
基本参数如下:
| |
| :——– | ——–:
| mlt | 是否开启推荐
| mlt| 推荐的字段
| mlt.mintf | 被关联文档里关键词出现次数多于这个值被忽略
| mlt.mindf| 所有文档里出现次数多于这个值的关键词被忽略
更详细的内容见https://cwiki.apache.org/confluence/display/solr/MoreLikeThis