目标:本文目标在于介绍java项目记录日志的主流方式log4j和tomcat log的配置方式和配合使用方法,
log4j(1.2.x)
log4j是Apache公司的一款用于在运行时输出日志的库。log4j的一个鲜明特征是它记录器(Logger)的分层记录,可以控制不同条件下输出日志的粒度,方便调试时获得详细信息和在正式环境减少日志输出量和存储成本。log4j目前支持的输出方式可以是文件,OutputStream,java.io.Writer,远程log4j服务器,远程Unix Syslog守护程序或许多其他输出目标。log4j的旧版本1.x是目前使用较多的旧版本。
log4j实现源码
查看源码有利于了解配置项结构和自定义log4j的日志输出,所以有必要进行源码分析。
为了查看log4j源码,打开我们的项目代码,容易疑惑的是:在我们代码中实际使用的Logger和LoggerFactory是org.slf4j包下的而不是log4j的包。slf4j这是java提供的简单日志接口定义,实际实现需要实现这些接口。用slf4j-log4j12-1.5.10.jar替换slf4j-jdk14-1.5.10.jar即可使用slf4j的接口,log4j的实现。
直接打开项目中引用的log4j.jar就可以看到它的源码,也可以在maven上下载log4j core只看核心类的代码。log4j的日志功能可以抽象出七个核心类/接口:Logger、LoggerRepository、Level、LoggingEvent、Appender、Layout、ObjectRender.类关系如下图:
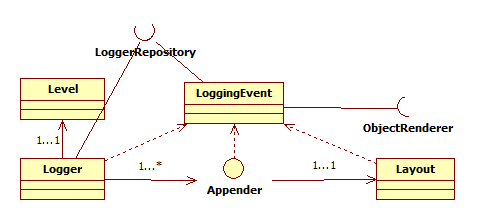
Logger用于对日志记录行为的抽象,提供记录不同级别日志的接口;Level对日志级别的抽象;Appender是对记录日志形式(xml、邮件、控制台输出)的抽象;Layout是对日志每行输出的格式的抽象;而LoggingEvent是对一次日志记录过程中所能取到信息的抽象(数据存储类)。LoggerRepository是Logger实例的容器,读取配置文件的信息也是这个类的功能,而ObjectRender是对日志实例的解析接口,处理传入的各类型Message。
每次执行一次类似于Logger.error()的语句写日志的时候,流程简略为:业务代码中调用Logger.xx()方法,Logger使用Level将此次调用请求等级与配置文件中等级对比,若本次请求等级更高,就继续日志输出的工作。之后Logger创建存储此次日志信息的LogEvent类,并作为参数传给Appender,Appender使用与自身一一关联的Layout类确定输出文本样式,随后由Appender将日志写入该Appender对应的日志输出中。流程图如下图所示。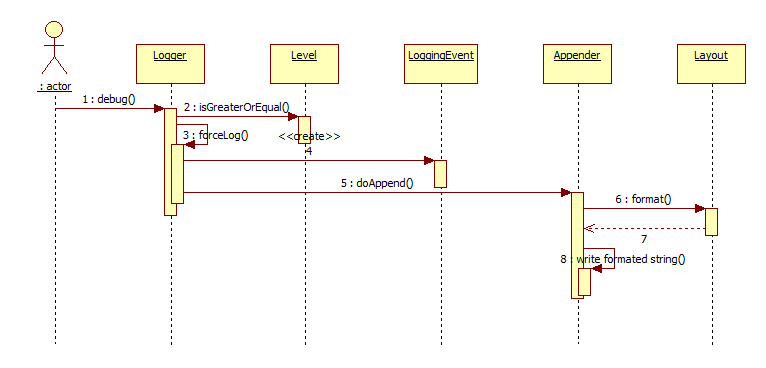
log4j使用配置
Log4j支持两种配置文件格式,一种是XML格式的文件,一种是properties文件。因为IT课现有项目大都使用的properties文件配置方式,所以先从在java项目中使用properties文件配置log4j写起:
导入必需jar包: 导入log4j ,slf4j(可选), slf4j-log4j (可选)三个jar包。
.properties的文件位置:.properties文件应该放在哪并且如何让项目知道它在哪?有三种方式
方法一:在web.xml中加入节点指定.properties文件位置,默认路径从source folder[ source folder:存放java源代码的文件夹,当然也包括一些package文件夹,还可以包含其他文件. 项目构建后,source folder里面的java自动编译成class文件到相应的/web-inf/classes文件夹中,其他文件也会移到/web-inf/classes相应的目录下. 在eclipse等ide中可以对文件夹右键→buildpath→use as source folder指定。一般可以新建一个source folder用于存放所有的配置文件.]开始
2
3
4
<param-name>log4jConfigLocation</param-name>
<param-value>/WEB-INF/log4j.properties</param-value>
</context-param>
方法二:在java代码中使用logger前初始化,默认路径一样从source folder开始,source folder:存放java源代码的文件夹,当然也包括一些package文件夹,还可以包含其他文件. 项目构建后,source folder里面的java自动编译成class文件到相应的/web-inf/classes文件夹中,其他文件也会移到/web-inf/classes相应的目录下. 在eclipse等ide中可以对文件夹右键→buildpath→use as source folder指定。一般可以新建一个source folder用于存放所有的配置文件。
方法三(现有项目使用的):log4j启动时,默认会寻找source folder下的log4j.xml配置文件,若没有,会寻找log4j.properties文件。然后加载配置。所以只要名字是log4j.properties并发在source folder下就可以了。
文件位置总结:现在部门中ssh项目大多使用的是第三种配置方式,配置简单方便,但是打包项目时一定会把配置文件也打进war包,如果要更改日志配置就得重启服务器。所以平时项目使用第三种配置,当预计日志需求变化较快时,使用前两种配置方式并把配置文件放到项目外更好。
编写.properties文件接下来开始编写properties文件自定义项目的日志输出。配置文件事实上也就是对上文说到的Logger、Appender及Layout进行相应设定。配置文件大致分为三个部分:
配置根Logger:
根Logger的配置格式为
log4j.rootLogger = [ level ] , appenderName1, appenderName2, …
log4j.additivity.org.apache=false:表示Logger不会在父Logger[2父Logger:可以限定某个类或包中使用另一种日志输出规则,如 log4j.logger.cn.server.child=error,E
rootlogger就是child Logger的父Logger]的appender里输出,默认为true。
level :设定日志记录的最低级别,可设的值有OFF、FATAL、ERROR、WARN、INFO、DEBUG、Trace、ALL或者自定义的级别,Log4j建议只使用中间四个(ERROR-DEBUG)级别。通过在这里设定级别,您可以控制应用程序中相应级别的日志信息的开关,比如在这里设定了INFO级别,则应用程序中所有DEBUG级别的日志信息将不会被打印出来。
appenderName:就是指定日志信息要使用哪几种方式输出。可以同时指定多个输出目的地,用逗号隔开。
例如:log4j.rootLogger=INFO,A1,B2,C
配置日志信息输出目的地(appender):
appender的配置格式为:
log4j.appender.appenderName = className
appenderName:自定义appderName,在log4j.rootLogger设置中使用;
className:可设值如下:
(1)org.apache.log4j.ConsoleAppender(控制台)
(2)org.apache.log4j.FileAppender(文件)
(3)org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)
(4)org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
(5)org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
下面介绍各类Appender具体的配置项:
ConsoleAppender选项:
2
3
ImmediateFlush=true:表示所有消息都会被立即输出,设为false则不输出,默认值是true。
Target=System.err:默认值是System.out。
FileAppender选项:
2
File=D:/logs/logging.log4j:指定消息输出到logging.log4j文件中。
DailyRollingFileAppender选项:
2
3
4
5
6
7
8
9
10
File=D:/logs/logging.log4j:指定当前消息输出到logging.log4j文件中。
DatePattern='.'yyyy-MM:每月滚动一次日志文件,即每月产生一个新的日志文件。当前月的日志文件名为logging.log4j,前一个月的日志文件名为logging.log4j.yyyy-MM。
另外,也可以指定按周、天、时、分等来滚动日志文件,对应的格式如下:
1)'.'yyyy-MM:每月
2)'.'yyyy-ww:每周
3)'.'yyyy-MM-dd:每天
4)'.'yyyy-MM-dd-a:每天两次
5)'.'yyyy-MM-dd-HH:每小时
6)'.'yyyy-MM-dd-HH-mm:每分钟
RollingFileAppender选项:
2
3
4
File=D:/logs/logging.log4j:指定消息输出到logging.log4j文件中。
MaxFileSize=100KB:后缀可以是KB, MB 或者GB。在日志文件到达该大小时,将会自动滚动,即将原来的内容移到logging.log4j.1文件中。
MaxBackupIndex=2:指定可以产生的滚动文件的最大数,例如,设为2则可以产生logging.log4j.1,logging.log4j.2两个滚动文件和一个logging.log4j文件。
配置日志信息的输出格式(Layout):
ayout的配置格式为:
log4j.appender.appenderName.layout=className
className:可设值如下:
(1)org.apache.log4j.HTMLLayout(以HTML表格形式布局)
(2)org.apache.log4j.PatternLayout(可以灵活地指定布局模式)
(3)org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串)
(4)org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
(1)HTMLLayout选项:
LocationInfo=true:输出java文件名称和行号,默认值是false。
Title=My Logging: 默认值是Log4J Log Messages。
(2)PatternLayout选项:
ConversionPattern=%m%n:设定以怎样的格式显示消息。
格式化符号说明:
%p:输出日志信息的优先级,即DEBUG,INFO,WARN,ERROR,FATAL。
%d:输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,如:%d{yyyy/MM/dd HH:mm:ss,SSS}。
%r:输出自应用程序启动到输出该log信息耗费的毫秒数。
%t:输出产生该日志事件的线程名。
%l:输出日志事件的发生位置,相当于%c.%M(%F:%L)的组合,包括类全名、方法、文件名以及在代码中的行数。例如:test.TestLog4j.main(TestLog4j.java:10)。
%c:输出日志信息所属的类目,通常就是所在类的全名。
%M:输出产生日志信息的方法名。
%F:输出日志消息产生时所在的文件名称。
%L::输出代码中的行号。
%m::输出代码中指定的具体日志信息。
%n:输出一个回车换行符,Windows平台为”rn”,Unix平台为”n”。
%x:输出和当前线程相关联的NDC(嵌套诊断环境),尤其用到像java servlets这样的多客户多线程的应用中。
%%:输出一个”%”字符。
另外,还可以在%与格式字符之间加上修饰符来控制其最小长度、最大长度、和文本的对齐方式。如:
1) c:指定输出category的名称,最小的长度是20,如果category的名称长度小于20的话,默认的情况下右对齐。
2)%-20c:”-“号表示左对齐。
3)%.30c:指定输出category的名称,最大的长度是30,如果category的名称长度大于30的话,就会将左边多出的字符截掉,但小于30的话也不会补空格。
屏蔽框架输出日志干扰
spring、hibernate、dubbo……这些框架使用commons-logging自动往我们的日志里塞内容导致日志过于庞大。让我们难以找到自己抛出的异常日志。
在log4j1.x的处理方法是根据实际使用框架的情况,定义对应的logger将它指定为OFF级别。1
2
3
4
5
6
7log4j.logger.org.springframework=OFF
log4j.logger.org.apache.struts2=OFF
log4j.logger.com.opensymphony.xwork2=OFF
log4j.logger.com.ibatis=OFF
log4j.logger.org.hibernate=OFF
log4j.logger.com.alibaba.dubbo=OFF
log4j.logger.org.apache.zookeeper=OFF
或者用限定包的logger代替rootlogger1
log4j.logger.com.tplink =org.apache.log4j.ConsoleAppender
配置文件总览
下面将展示log4j的整体配置
同项目内多个logger配置
在配置文件中,新写一个类似于rootlogger定义的语句用来定义子logger1
2#指定tplink.Newlogger类专用的logger
log4j.logger.tplink.Newlogger= DEBUG, test
然后在业务代码中我们就可以获取这个自定义的logger1
Logger logger = LoggerFactory.getLogger(Newlogger.class); //参数是class
或者不是指定类而是一个名字来定义logger1
log4j.logger.myTest= DEBUG, test2
业务代码中使用String来获取logger1
Logger logger = LoggerFactory.getLogger(“myTest”); //参数是string
自定义Appender
在源码中有一个AppenderSkeleton骨架类,自己写一个类继承它。除了override方法外,自己需要从配置项读取的变量定义后写好getter和setter,就可以自动注入了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import org.apache.log4j.AppenderSkeleton;
import org.apache.log4j.spi.LoggingEvent;
public class IMAppender extends AppenderSkeleton {
private String username; //从配置文件读取的变量
public void close() {
// TODO Auto-generated method stub
}
public boolean requiresLayout() {
// TODO Auto-generated method stub
return false;
}
protected void append(LoggingEvent event) {
System.out.println("Hello, " + username + " : "+ event.getMessage());
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
}
日志性能优化
影响性能最明显的几个步骤:硬盘读写、网络读写、JDBC,所以优化性能从这几点考虑。
设置日志缓存,以及缓存大小1
2
3log4j.appender.A3.BufferedIO=true
#BufferSize单位为字节,默认是8K
log4j.appender.A3.BufferSize=8192
如果日志性能不佳,放弃数据库日志和邮件日志
在log4j1中的异步日志性能较差且容易出现死锁,不建议使用
使用xml配置
因为我们部门在log4j的使用中习惯用.properties文件,而xml在log4j2里被推荐使用,所以在log4j2部分里再作详细介绍。
log4j2
在log4j的官网上已经给出声明,自 2015-8-5起log4j已经是”reach end of life”,推荐将log4j更新到log4j2。log4j2的使用方式相比较1并没有太大改变,除了配置方式推荐为xml外,在与slf4j的协同上没有改变,也不需要改变旧java代码。(如果需要使用log4j2在java代码中的新特性就得替换slf4j的org.slf4j.LoggerFactory为org.apache.logging.log4j.LogManager)
2.1.log4j2优点
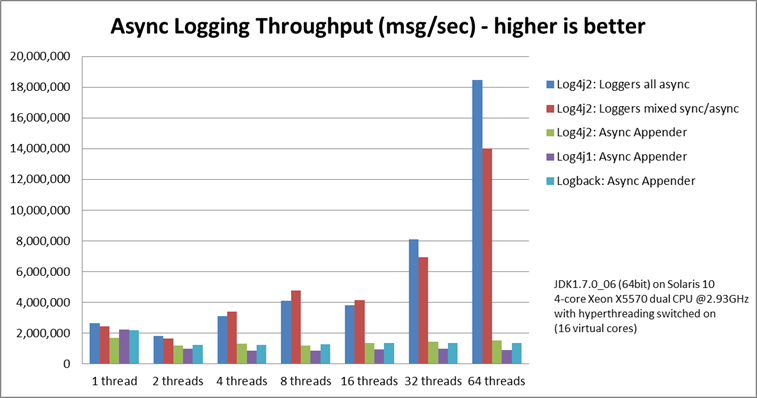
log4j2相比1有更好的异步日志性能,下图是官网上的日志吞吐量比较。同时log4j2也解决了1中高并发时出现的大量死锁问题。
log4j2支持变量参数的占位符功能
log4j2的执行记录跟踪和日志标签
这两个功能类似,都相当于给日志加上分隔符和类似android logcat的日志标签,用于区分不同模块的日志,省去了在日志字符串中作区分的麻烦。如果要使用的话可以参考官网链接Flow Tracing,Markers。
log4j2的使用配置
导入包
在项目中导入log4j-core-2.x.jar log4j-api-2.x.jar两个包。
配置文件
log4j2支持的配置方式有 XML, JSON, YAML,properties(版本2.4后支持properties方式,但是和1中的配置方式也不再相同)。
和1一样log4j2也会在classpath自动寻找配置文件,优先级从高到低分别为log4j2-test.properties,log4j2-test.yaml,log4j2-test.json,log4j2-test.xml,log4j2.properties,log4j2.yaml,log4j2.json,log4j2.xml。在没有找到配置文件时,会使用默认配置,输出到控制台。
xml配置
改为xml配置后,log4j要配置的依然是appender、layout、logger三部分。内容与1中的properties文件没有太大差别。下面举个例子:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
<!--先定义默认的日志级别-->
<configuration status="error">
<!--先定义所有的appender-->
<appenders>
<!--这个输出控制台的配置 节点名字是随便起的 name属性下面配置logger要用到-->
<Console name="Console" target="SYSTEM_OUT">
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)-->
<ThresholdFilter level="trace" onMatch="ACCEPT" onMismatch="DENY"/>
<!—和1一样的layout,具体配置也没变-->
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</Console>
<!--文件会打印出所有信息,这个log每次运行程序会自动清空,由append属性决定,这个也挺有用的,适合临时测试用-->
<File name="log" fileName="log/test.log" append="false">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</File>
<!--这个会打印出所有的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档-->
<RollingFile name="RollingFile" fileName="logs/app.log"
filePattern="log/$${date:yyyy-MM}/app-%d{MM-dd-yyyy}-%i.log.gz">
<PatternLayout pattern="%d{yyyy-MM-dd 'at' HH:mm:ss z} %-5level %class{36} %L %M - %msg%xEx%n"/>
<SizeBasedTriggeringPolicy size="50MB"/>
</RollingFile>
</appenders>
<!--然后定义logger-->
<loggers>
<!--建立一个默认的root的logger-->
<root level="trace">
<appender-ref ref="RollingFile"/>
<appender-ref ref="Console"/>
</root>
<!—为某个类定义一个logger,name是该类的包路径,如果没有这个类就会视为普通的string命名的logger,log4j2会根据包名决定继承关系”com.tplink”logger就会是下面logger的父logger,additivity决定日志是否需要按照父logger再打印一次-->
<root name="com.tplink.mi.TestClass" level="trace" additivity="false">
<appender-ref ref="RollingFile"/>
<appender-ref ref="Console"/>
</root>
</loggers>
</configuration>
在例子中可以看到log4j的级别、appender种类和配置项、logger的继承关系、logger和类的绑定都没变。只是appender和logger的配置被不同节点分开,原来用键值对配置的属性改为标签内的属性配置。
在java代码中,如果不使用slf4j的话,使用如下语句创建Logger对象和打印日志1
2Logger logger = LogManager.getLogger(Test.class.getName());
logger.error("error");
log4j迁移到log4j2
更改引用的包
更改pom.xml配置,删除log4j的引用和低版本slf4j的引用,换成log4j2.x的引用例如1
2
3
4
5<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.1</version>
</dependency>
换成1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.6.2</version>
</dependency>
<!-- log4j-slf4j-impl(用于log4j2与slf4j集成) -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.6.2</version>
</dependency>
如果不用slf4j那只要引入log4jcore和api两个包就行了1
2
3
4
5
6
7
8
9
10<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.6.2</version>
</dependency>
更改配置文件
因为log4j的log4j.properties配置方式在2中不再被支持,所以更新log4j.properties
的配置方式或者删除后换成log4j.xml。新的log4j.properties格式和xml配置类似,也是先定义appender再定义logger。例如官网上的例子:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
dest = err
name = PropertiesConfig
property.filename = target/rolling/rollingtest.log
filter.threshold.type = ThresholdFilter
filter.threshold.level = debug
appender.console.type = Console
appender.console.name = STDOUT
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %m%n
appender.rolling.type = RollingFile
appender.rolling.name = RollingFile
appender.rolling.fileName = ${filename}
appender.rolling.filePattern = target/rolling2/test1-%d{MM-dd-yy-HH-mm-ss}-%i.log.gz
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d %p %C{1.} [%t] %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 2
appender.rolling.policies.time.modulate = true
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 5
appender.list.type = List
appender.list.name = List
appender.list.filter.threshold.type = ThresholdFilter
appender.list.filter.threshold.level = error
logger.rolling.name = com.example.my.app
logger.rolling.level = debug
logger.rolling.additivity = false
logger.rolling.appenderRef.rolling.ref = RollingFile
rootLogger.level = info
rootLogger.appenderRef.stdout.ref = STDOUT
更新java代码中的Logger(可选)
之前使用的slf4.org.Logger可以替换成org.apache.logging.log4j.Logger用于使用变量参数的占位符功能。如果应用了slf4j的包,也可以不改任何代码,继续使用slf4.org.Logger。
屏蔽框架输出日志干扰
spring、hibernate、dubbo……这些框架使用commons-logging自动往我们的日志里塞内容导致日志过于庞大。让我们难以找到自己抛出的异常日志。
在log4j2的处理方法是根据实际使用框架的情况,定义对应的logger将它指定为OFF级别。1
2<logger name="org.springframework" level="off" additivity="false">
</logger>
或者在要使用的日志中指定name为自己的包名如”com.tplink”,就只输出这个包的日志。
也可以提升整体日志级别到error,因为一般这些框架输出的级别都在debug和info。1
2
3<logger name="com.tplink.ebs" level="off" additivity="false">
<appender-ref ref="Console"/>
</logger>
Tomcat日志
本部分基于apache tomcat版本7.0-8.5。
Tomcat日志种类介绍
tomcat下的日志种类繁多,观察tomcat的日志目录(一般为..\logs)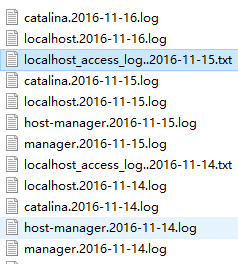
可以看到tomcat的日志分为:
|日志种类\作用 | 文件名
| :——– | ——–:
| Cataline引擎的日志文件、控制台输出的日志 | catalina.日期.log
| Tomcat下内部代码丢出的日志| localhost.日期.log
| Tomcat下默认manager应用日志| manager.日期.log
|Access日志|文件名在Servlet.xml配置(一般叫localhost_access_log..日期.log)
|log4j配置存储到该目录下的日志|随配置改变
catalina.log我们在维护时常看的日志之一,因为在我们的旧项目中,如果log4j指定的输出方式为stdout,那么在unix类系统中会被重定向到catalina.log中。除此之外,它还包含catalina引擎——tomcat的servlet容器本身的报错日志。
localhost.log中的内容是jsp页面内部错误的异常。
manager.log 是tomcat自带的manager应用的日志,正式项目中一般不开启manager应用。
localhost_access_log.log 是记录访问者、访问日期、访问目标的日志。
Tomcat日志配置
默认JULI实现下的配置
JULI,指tomcat对java.util.logging API的实现,用于负责日志输出。tomcat也可以通过配置让log4j来负责它的日志。
根据官方文档,Tomcat支持各应用各自独立使用日志框架。而Tomcat本身的通用日志系统,即用来输出上文所介绍的catalina.log, localhost.log,manager.log 的日志系统,是默认通过”JULI”实现的。
默认Tomcat使用JULI的情况下,并且除了常规的全局java.util.logging配置之外,还支持不同的应用使用不同的配置。全局的配置通常在$ {catalina.base} /conf/logging.properties文件中完成。该文件由java.util.logging.config.file系统属性指定,该属性由启动脚本设置。如果它不可读或未配置,则默认使用JRE中的$ {java.home} /lib/logging.properties文件。
在各Web应用程序中。该文件将是WEB-INF / classes / logging.properties。
logging.properties配置和java.util.logging的配置方式相似,一样有区分输出级别,从高到低分别是OFF,SEVERE,WARNING,INFO,CONFIG,FINE,FINER,FINEST或ALL设置。处理程序的日志级别阈值默认为INFO,同样,不同包也可以指定不同的日志级别。
logging.properties的三段结构
logging.properties配置文件由3大部分组成:起始handler申明,配置handler属性,logger适配handler。配置中的handler类似于log4j中的appender,用于指定日志的输出目标;formatter类似于layout,用于指定日志的格式;logger则是记录日志的执行类。
下面是示例logging.properties配置:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#定义handlers,handlers名称格式为 前缀.决定输出目的的handler类
handlers=1catalina.org.apache.juli.FileHandler,2localhost.org.apache.juli.FileHandler, 3manager.org.apache.juli.FileHandler, java.util.logging.ConsoleHandler
.handlers = 1catalina.org.apache.juli.FileHandler, java.util.logging.ConsoleHandler
############################################################
#配置handler属性
############################################################
# Cataline引擎的日志文件,文件名catalina.日期.log
1catalina.org.apache.juli.FileHandler.level = FINE
1catalina.org.apache.juli.FileHandler.directory = ${catalina.base}/logs
1catalina.org.apache.juli.FileHandler.prefix = catalina.
# Tomcat下内部代码丢出的日志,文件名localhost.日期.log
2localhost.org.apache.juli.FileHandler.level = FINE
2localhost.org.apache.juli.FileHandler.directory = ${catalina.base}/logs
2localhost.org.apache.juli.FileHandler.prefix = localhost.
# Tomcat下默认manager应用日志,文件名manager.日期.log
3manager.org.apache.juli.FileHandler.level = FINE
3manager.org.apache.juli.FileHandler.directory = ${catalina.base}/logs
3manager.org.apache.juli.FileHandler.prefix = manager.
# 控制台输出的日志,Linux下默认重定向到catalina.out
java.util.logging.ConsoleHandler.level = FINE
java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
############################################################
# logger适配handler
############################################################
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].level = INFO
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].handlers = 2localhost.org.apache.juli.FileHandler
# manager的日志
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/manager].level = INFO
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/manager].handlers=3manager.org.apache.juli.FileHandler
# host-manager的日志
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/host-manager].level = INFO
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/host-manager].handlers=4host-manager.org.apache.juli.FileHandler
handler申明中给handler命名格式为“前缀. handler类名”:前缀是数字开头小数点结尾的字符串,用于区分同类的不同handler。handler类决定日志输出形式,这个类有如下表格中的几种实现,不同handler的配置项如最右一栏所示:
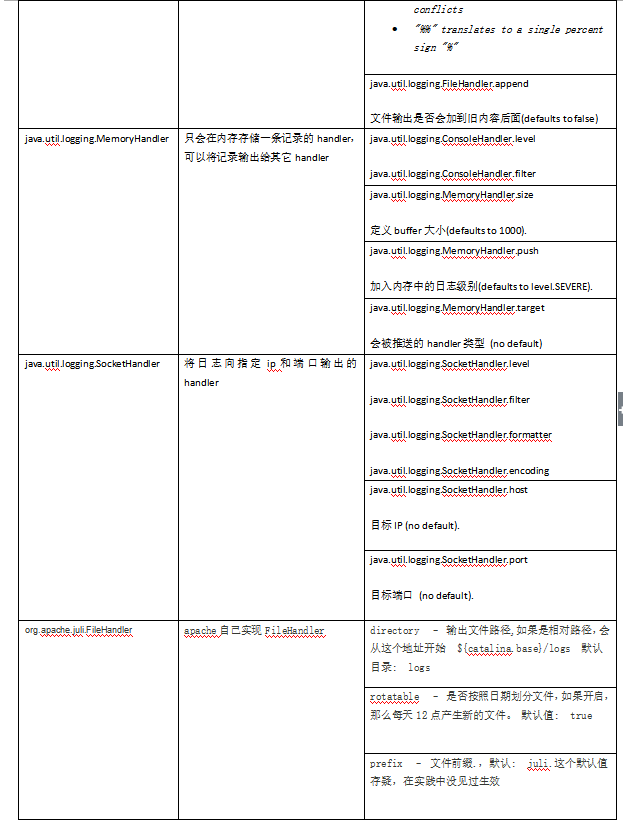

定义并配置handler之后,需要将handeler绑定给logger,logger的命名方式是org.apache.catalina.core.ContainerBase.[${engine}].[${host}].[${context}] ,其中Engine一般是Catalina——tomcat的servlet引擎,context即是tomcat日志的那些种类:“localhost、host-manager”……
Access Logging的特殊性
在上述日志中,有一个特例Access访问日志:因为它需要以较低的开销快速频繁地记录来访情况,所以它并没有使用JULI来实现它在Servlet.xml中的Context或者 Host或者Engine中配置。在上述的配置节中增加类似的value:1
2
3<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log." suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
Access Logging同样有一系列配置项,以下翻译自官网:
|参数 | 描述
| :——– | ——–:
| className | 实现类的类名,如果要用默认方式实现日志那就一定设为 org.apache.catalina.valves.AccessLogValve
| directory| 文件存放路径,如果是相对路径那么会从$CATALINA_BASE算起。默认值是 “logs”
| prefix| 文件名前缀,默认”access_log.”.
|suffix|文件名后缀,默认为空字符串
|fileDateFormat|自定义在文件名中的时间戳默认值yyyy-MM-dd. 如果你希望每小时刷新一个文件那么改成 yyyy-MM-dd.HH.日期一定会使用 en_US配置本地化。
|rotatable|是否需要划分日志文件,默认: true
|renameOnRotate|是否禁用分割文件中的timestamp,默认: false
|pattern|日志输出的文本的格式
|encoding|编码
|locale|用于在访问日志行中格式化时间戳的语言环境。 使用显式SimpleDateFormat模式(%{xxx} t)配置的任何时间戳都将在此语言环境中进行格式化。 默认情况下使用Java进程的缺省语言环境。
|requestAttributesEnabled|是否显示远程请求传来的参数,默认为false
|conditionIf|启用条件日志记录。 如果设置,只有当ServletRequest.getAttribute()不为null时,才会记录请求。 例如,如果此值设置为important,那么只有ServletRequest.getAttribute(“important”)!= null时才会记录特定的请求。 使用过滤器是一种在许多不同请求上在ServletRequest中设置/取消设置属性的简单方法。
|conditionUnless|和上条类似,不过变为ServletRequest.getAttribute(“important”)== null时才会记录特定的请求。
|condition|和conditionUnless一样,这个属性用于向后兼容
|buffered|决定是否启用缓存,默认: true
其中pattern属性时决定日志输出格式的重要属性,它的语法很复杂,但是可以用短配置简化:shorthand pattern pattern=”common” 代表 ‘%h %l %u %t “%r” %s %b’。更详细的语法如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28%a - Remote IP address
%A - Local IP address
%b - Bytes sent, excluding HTTP headers, or '-' if zero
%B - Bytes sent, excluding HTTP headers
%h - Remote host name (or IP address if enableLookups for the connector is false)
%H - Request protocol
%l - Remote logical username from identd (always returns '-')
%m - Request method (GET, POST, etc.)
%p - Local port on which this request was received. See also %{xxx}p below.
%q - Query string (prepended with a '?' if it exists)
%r - First line of the request (method and request URI)
%s - HTTP status code of the response
%S - User session ID
%t - Date and time, in Common Log Format
%u - Remote user that was authenticated (if any), else '-'
%U - Requested URL path
%v - Local server name
%D - Time taken to process the request, in millis
%T - Time taken to process the request, in seconds
%F - Time taken to commit the response, in millis
%I - Current request thread name (can compare later with stacktraces)
%{xxx}i write value of incoming header with name xxx
%{xxx}o write value of outgoing header with name xxx
%{xxx}c write value of cookie with name xxx
%{xxx}r write value of ServletRequest attribute with name xxx
%{xxx}s write value of HttpSession attribute with name xxx
%{xxx}p write local (server) port (xxx==local) or remote (client) port (xxx=remote)
%{xxx}t write timestamp at the end of the request formatted using the enhanced SimpleDateFormat pattern xxx
值得一提的是,在观察Access Log后可能产生过滤某些请求的需求,而和AccessLogging相关的功能Access Control可以过滤访问请求。详细可以去官网文档查看。
2.2.使用Log4j实现Tomcat日志
本节介绍如何配置Tomcat以对所有Tomcat的内部日志记录使用log4j而不是java.util.logging。
注意:这和我们在项目中使用log4j完全不是一回事,是指用log4j代替JULI实现Tomcat的系统日志。这种替换目的在于使用更加友好的配置方式和更丰富的日志输出方式。
以下步骤描述了如何配置log4j以输出Tomcat的内部日志记录。
创建log4j.properties配置文件
下载log4j v1.2.x
在apache tomcat官网下载tomcat-juli.jar 、 tomcat-juli-adapters.jar
把log4j.jar 和tomcat-juli-adapters.jar放到tomcat下 的lib文件夹里
把bin文件夹下的tomcat-juli.jar用刚刚下载的版本代替
删除conf文件夹下的logging.properties文件,防止tomcat生成空日志文件
开启tomcat
其中log4j.properties的配置和普通log4j一样,只要保证logger的名称是tomcat规定的格式
org.apache.catalina.core.ContainerBase.[${engine}].[${host}].[${context}] 格式。例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
log4j.rootLogger = INFO, CATALINA
# Define all the appenders
log4j.appender.CATALINA = org.apache.log4j.DailyRollingFileAppender
log4j.appender.CATALINA.File = ${catalina.base}/logs/catalina
log4j.appender.CATALINA.Append = true
log4j.appender.CATALINA.Encoding = UTF-8
# Roll-over the log once per day
log4j.appender.CATALINA.DatePattern = '.'yyyy-MM-dd'.log'
log4j.appender.CATALINA.layout = org.apache.log4j.PatternLayout
log4j.appender.CATALINA.layout.ConversionPattern = %d [%t] %-5p %c- %m%n
log4j.appender.LOCALHOST = org.apache.log4j.DailyRollingFileAppender
log4j.appender.LOCALHOST.File = ${catalina.base}/logs/localhost
log4j.appender.LOCALHOST.Append = true
log4j.appender.LOCALHOST.Encoding = UTF-8
log4j.appender.LOCALHOST.DatePattern = '.'yyyy-MM-dd'.log'
log4j.appender.LOCALHOST.layout = org.apache.log4j.PatternLayout
log4j.appender.LOCALHOST.layout.ConversionPattern = %d [%t] %-5p %c- %m%n
log4j.appender.MANAGER = org.apache.log4j.DailyRollingFileAppender
log4j.appender.MANAGER.File = ${catalina.base}/logs/manager
log4j.appender.MANAGER.Append = true
log4j.appender.MANAGER.Encoding = UTF-8
log4j.appender.MANAGER.DatePattern = '.'yyyy-MM-dd'.log'
log4j.appender.MANAGER.layout = org.apache.log4j.PatternLayout
log4j.appender.MANAGER.layout.ConversionPattern = %d [%t] %-5p %c- %m%n
log4j.appender.HOST-MANAGER = org.apache.log4j.DailyRollingFileAppender
log4j.appender.HOST-MANAGER.File = ${catalina.base}/logs/host-manager
log4j.appender.HOST-MANAGER.Append = true
log4j.appender.HOST-MANAGER.Encoding = UTF-8
log4j.appender.HOST-MANAGER.DatePattern = '.'yyyy-MM-dd'.log'
log4j.appender.HOST-MANAGER.layout = org.apache.log4j.PatternLayout
log4j.appender.HOST-MANAGER.layout.ConversionPattern = %d [%t] %-5p %c- %m%n
log4j.appender.CONSOLE = org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Encoding = UTF-8
log4j.appender.CONSOLE.layout = org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern = %d [%t] %-5p %c- %m%n
# Configure which loggers log to which appenders
log4j.logger.org.apache.catalina.core.ContainerBase.[Catalina].[localhost] = INFO, LOCALHOST
log4j.logger.org.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/manager] =\
INFO, MANAGER
log4j.logger.org.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/host-manager] =\
INFO, HOST-MANAGER
Tomcat+log4j日志方案示例
开发环境推荐配置
以下配置的目的:在控制台只输出所有代码中抛出的debug级别及以上的日志信息,并在文件中保留当次启动的输出日志便于复查。
达成上面目标的主要困难是:
1.使用相对路径时,日志文件很难找
这里的处理方法是在windows中干脆用绝对路径
也可以使用log4j2的特性lookup,${log4j:configParentLocation}定位到配置文件的上级目录,${sys:catalina.home}定位到tomcat目录
2.spring、hibernate、dubbo……这些框架使用commons-logging自动往我们的日志里塞内容导致日志过于庞大
这里的处理方法是根据实际使用框架的情况,定义对应的logger将它指定为OFF级别。
或者在要使用的日志中指定name为自己的包名如”com.tplink”,就只输出这个包的日志。
也可以提升整体日志级别到error,因为一般这些框架输出的级别都在debug和info。
pom.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.6.2</version>
</dependency>
<!-- log4j-slf4j-impl(用于log4j2与slf4j集成) -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.6.2</version>
</dependency>
1 | <?xml version="1.0" encoding="UTF-8"?> |
查找特定bug时的推荐配置
和开发情况下的配置类似,只是loggers需要限定到疑似出现问题的特定包、类就可以1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30<?xml version="1.0" encoding="UTF-8"?>
<!--先定义默认的日志级别-->
<configuration status="debug">
<!--先定义所有的appender-->
<ThresholdFilter level="debug" onMatch="ACCEPT" onMismatch="DENY"/>
<appenders>
<!--这个输出控制台的配置 节点名字是Appender name属性下面配置logger要用到-->
<Console name="Console" target="SYSTEM_OUT" additivity="true">
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)-->
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</Console>
<!--文件会打印出所有信息,这个log每次运行程序会自动清空,由append属性决定,这个也挺有用的,适合临时测试用-->
<File name="test" fileName="d:/logs/test.log" append="false" additivity="true">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</File>
<!—也可以使用项目目录存放日志文件 -->
<!--<File name="test" fileName="${log4j:configParentLocation}/logs/test.log" append="false" additivity="true">-->
<!--<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>-->
<!--</File> -->
</appenders>
<!--然后定义logger-->
<loggers>
<logger name="com.tplink.ebs" level="off" additivity="false">
<appender-ref ref="Console"/>
</logger>
</loggers>
</configuration>
测试、正式环境推荐配置
和现在项目相比,这种配置的目的是削减catalina.out的输出,作为替换用log4j的文件记录每天的日志。
log4j2.xml
配置的目的是设置两个文件MITP.log和MIFULL.log分别输出自己代码的异常和全部异常,在文件大小达到SizeBasedTriggeringPolicy设置的值后,会按日期分文件夹并存为压缩文件。文件存放地点是tomcat目录下的logs文件夹1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37<?xml version="1.0" encoding="UTF-8"?>
<!--先定义默认的日志级别-->
<configuration status="error">
<!--先定义所有的appender-->
<appenders>
<!--这个输出控制台的配置 节点名字是Appender name属性下面配置logger要用到-->
<Console name="Console" target="SYSTEM_OUT">
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)-->
<ThresholdFilter level="error" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</Console>
<!--这个会打印出所有的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档-->
<RollingFile name="RollingFileFull" fileName="${sys:catalina.home}/logs/MIFull.log"
filePattern="${sys:catalina.home}/logs/$${date:yyyy-MM}/MIFULL-%d{MM-dd-yyyy}-%i.log.gz">
<PatternLayout pattern="%d{yyyy-MM-dd 'at' HH:mm:ss z} %-5level %class{36} %L %M - %msg%xEx%n"/>
<SizeBasedTriggeringPolicy size="50MB"/>
</RollingFile>
<RollingFile name="RollingFileTP" fileName="${sys:catalina.home}/logs/MITP.log"
filePattern="${sys:catalina.home}/logs/$${date:yyyy-MM}/MITP-%d{MM-dd-yyyy}-%i.log.gz">
<PatternLayout pattern="%d{yyyy-MM-dd 'at' HH:mm:ss z} %-5level %class{36} %L %M - %msg%xEx%n"/>
<SizeBasedTriggeringPolicy size="50MB"/>
</RollingFile>
</appenders>
<!--然后定义logger-->
<loggers>
<!--建立一个默认的root的logger-->
<root level="error" additivity="true">
<appender-ref ref="RollingFileFull"/>
</root>
<logger name="com.tplink" level="error" additivity="true">
<appender-ref ref="RollingFileTP"/>
</logger>
</loggers>
</configuration>
tomcat logging.properties
和默认配置文件比只改了Catalina的输出级别为OFF1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
handlers = 1catalina.org.apache.juli.FileHandler, 2localhost.org.apache.juli.FileHandler, 3manager.org.apache.juli.FileHandler, 4host-manager.org.apache.juli.FileHandler, java.util.logging.ConsoleHandler
.handlers = 1catalina.org.apache.juli.FileHandler, java.util.logging.ConsoleHandler
############################################################
# Handler specific properties.
# Describes specific configuration info for Handlers.
############################################################
1catalina.org.apache.juli.FileHandler.level = FINE
1catalina.org.apache.juli.FileHandler.directory = ${catalina.base}/logs
1catalina.org.apache.juli.FileHandler.prefix = catalina.
2localhost.org.apache.juli.FileHandler.level = FINE
2localhost.org.apache.juli.FileHandler.directory = ${catalina.base}/logs
2localhost.org.apache.juli.FileHandler.prefix = localhost.
3manager.org.apache.juli.FileHandler.level = FINE
3manager.org.apache.juli.FileHandler.directory = ${catalina.base}/logs
3manager.org.apache.juli.FileHandler.prefix = manager.
4host-manager.org.apache.juli.FileHandler.level = FINE
4host-manager.org.apache.juli.FileHandler.directory = ${catalina.base}/logs
4host-manager.org.apache.juli.FileHandler.prefix = host-manager.
java.util.logging.ConsoleHandler.level = OFF
java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
############################################################
# Facility specific properties.
# Provides extra control for each logger.
############################################################
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].level = ERROR
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].handlers = 2localhost.org.apache.juli.FileHandler
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/manager].level = ERROR
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/manager].handlers = 3manager.org.apache.juli.FileHandler
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/host-manager].level = ERROR
org.apache.catalina.core.ContainerBase.[Catalina].[localhost].[/host-manager].handlers = 4host-manager.org.apache.juli.FileHandler
# For example, set the org.apache.catalina.util.LifecycleBase logger to log
# each component that extends LifecycleBase changing state:
#org.apache.catalina.util.LifecycleBase.level = FINE
# To see debug messages in TldLocationsCache, uncomment the following line:
#org.apache.jasper.compiler.TldLocationsCache.level = FINE